Waarom u de indrukwekkende tekst-naar-afbeelding-generator van Google nog niet kunt gebruiken Met de tekst-naar-beeld-synthesizer van Google, Imagen, kunnen gebruikers elke mogelijkheid bedenken, inclusief een corgi in een sushi-huis. Google Onderzoek, Hersenteam Dit artikel stond oorspronkelijk op Popular Photography. Acute corgi woont in een huis gemaakt van sushi. Een drakenvrucht die een karateriem in de sneeuw draagt. Een brein dat op een raketschip op weg is naar de maan. Dit zijn slechts enkele van de door AI gegenereerde afbeeldingen die zijn geproduceerd door Google's Imagen-tekst-naar-afbeelding-diffusiemodel, en de resultaten zijn ongelooflijk nauwkeurig, soms met humor. Onderzoekers van Google hebben deze resultaten onlangs onthuld in een paper die vorige maand is gepubliceerd – en bespraken de morele gevolgen die het gebruik van deze nieuwste technologie met zich meebrengt. Google's Imagen verslaat de concurrentie In hun onderzoekspaper bevestigden computerwetenschappers van Google dat bestaande, vooraf getrainde grote taalmodellen redelijk goed presteren bij het maken van afbeeldingen op basis van tekstinvoer. Met Imagen hebben ze eenvoudig de grootte van het taalmodel vergroot en ontdekten dat dit tot nauwkeurigere resultaten leidde. De FID-score van Imagen scoorde ruim boven andere tekst-naar-beeld-synthesizers. Google Onderzoek, Hersenteam Om de resultaten te meten, gebruikte Imagen de Common Objects in Context (COCO) dataset, een open-source compendium van visuele datasets waarop bedrijven en onderzoekers hun AI-algoritmen kunnen trainen in beeldherkenning. De modellen ontvangen een Frechet Inception Distance (FID)-score, die hun nauwkeurigheid berekent bij het weergeven van een afbeelding op basis van aanwijzingen uit de dataset. Een lagere score geeft aan dat er meer overeenkomsten zijn tussen de echte en gegenereerde afbeeldingen, met een perfecte score van 0,0. Google's Imagen-diffusiemodel kan 1024-bij-1024-pixel voorbeeldafbeeldingen maken met een FID-score van 7,27. Volgens de onderzoekspaper staat Imagen bovenaan de hitlijsten met zijn FID-score in vergelijking met andere modellen, waaronder DALL-E 2, VQ-GAN+CLIP en Latent Diffusion Models. Bevindingen gaven aan dat Imagen ook de voorkeur had van menselijke beoordelaars. Een drakenvrucht die een karateriem draagt, is slechts een van de vele afbeeldingen die Imagen kan maken. Google Onderzoek, Hersenteam "Voor fotorealisme behaalt Imagen een voorkeurspercentage van 39,2%, wat wijst op een hoge beeldkwaliteit", melden computerwetenschappers van Google. “Op de set zonder mensen is het voorkeurspercentage van Imagen gestegen tot 43,6%, wat wijst op het beperkte vermogen van Imagen om fotorealistische mensen te genereren. Wat de gelijkenis van bijschriften betreft, is de score van Imagen vergelijkbaar met de originele referentiebeelden, wat suggereert dat Imagen in staat is om afbeeldingen te genereren die goed aansluiten bij COCO-onderschriften.” Naast de COCO-dataset heeft het Google-team ook hun eigen dataset gemaakt, die ze DrawBench noemden. De benchmark bestaat uit rigoureuze scenario's die het vermogen van verschillende modellen testten om afbeeldingen te synthetiseren op basis van "compositionaliteit, kardinaliteit, ruimtelijke relaties, lange tekst, zeldzame woorden en uitdagende prompts", die verder gaan dan de meer beperkte COCO-prompts. Hoewel leuk, de technologie presenteert morele en ethische dilemma's. Google Onderzoek, Hersenteam Morele implicaties van Imagen en andere AI tekst-naar-beeld software Er is een reden waarom alle voorbeeldafbeeldingen geen mensen hebben. In hun conclusie bespreekt het Imagen-team de mogelijke morele gevolgen en maatschappelijke impact van de technologie, wat niet altijd het beste is. Het programma vertoont nu al een westerse vooringenomenheid en standpunt. Hoewel we erkennen dat er een potentieel is voor eindeloze creativiteit, zijn er helaas ook mensen die zouden kunnen proberen de software te misbruiken. Het is onder meer om deze reden dat Imagen niet beschikbaar is voor openbaar gebruik, maar dat kan veranderen. "Aan de andere kant kunnen generatieve methoden worden gebruikt voor kwaadaardige doeleinden, waaronder intimidatie en de verspreiding van verkeerde informatie, en veel zorgen oproepen over sociale en culturele uitsluiting en vooroordelen", schrijven de onderzoekers. “Deze overwegingen vormen de basis voor onze beslissing om geen code of een openbare demo vrij te geven. In toekomstige werkzaamheden zullen we een raamwerk voor verantwoorde externalisering onderzoeken dat de waarde van externe controle in evenwicht houdt met de risico's van onbeperkte open toegang." De onderzoekers erkennen dat er meer werk nodig is voordat Imagen op verantwoorde wijze aan het publiek kan worden vrijgegeven. Google Onderzoek, Hersenteam Bovendien merkten de onderzoekers op dat vanwege de beschikbare datasets waarop Imagen is getraind, het programma vooringenomen is. "Dataset-audits hebben aangetoond dat deze datasets vaak sociale stereotypen, onderdrukkende standpunten en denigrerende of anderszins schadelijke associaties met gemarginaliseerde identiteitsgroepen weerspiegelen." Hoewel de technologie zeker leuk is (wie wil er nu niet een afbeelding van een buitenaardse octopus die door een portaal zweeft terwijl hij een krant leest?), is het duidelijk dat er meer werk en onderzoek voor nodig is voordat Imagen (en andere programma's) kan worden verantwoord vrijgegeven aan het publiek. Sommige, zoals Dall-E 2, hebben beveiligingen ingezet, maar de doeltreffendheid valt nog te bezien. Imagen erkent de gigantische, maar noodzakelijke taak om de negatieve gevolgen grondig te verzachten. "Hoewel we deze uitdagingen in dit werk niet direct aanpakken, is het besef van de beperkingen van onze trainingsgegevens leidend bij onze beslissing om Imagen niet vrij te geven voor openbaar gebruik", besluiten ze. "We waarschuwen ten zeerste tegen het gebruik van tekst-naar-afbeelding-generatiemethoden voor gebruikersgerichte tools zonder zorgvuldige zorg en aandacht voor de inhoud van de trainingsdataset." Het bericht Waarom je Google's indrukwekkende tekst-naar-beeldgenerator Imagen niet kunt gebruiken, verscheen nog eerst op Popular Science.


Dit artikel stond oorspronkelijk op Popular Photography.
Acute corgi woont in een huis gemaakt van sushi. Een drakenvrucht die een karateriem in de sneeuw draagt. Een brein dat op een raketschip op weg is naar de maan. Dit zijn slechts enkele van de door AI gegenereerde afbeeldingen die zijn geproduceerd door Google's Imagen-tekst-naar-afbeelding-diffusiemodel, en de resultaten zijn ongelooflijk nauwkeurig, soms met humor. Onderzoekers van Google hebben deze resultaten onlangs onthuld in een paper die vorige maand is gepubliceerd – en bespraken de morele gevolgen die het gebruik van deze nieuwste technologie met zich meebrengt.
Google's Imagen verslaat de concurrentie
In hun onderzoekspaper bevestigden computerwetenschappers van Google dat bestaande, vooraf getrainde grote taalmodellen redelijk goed presteren bij het maken van afbeeldingen op basis van tekstinvoer. Met Imagen hebben ze eenvoudig de grootte van het taalmodel vergroot en ontdekten dat dit tot nauwkeurigere resultaten leidde.
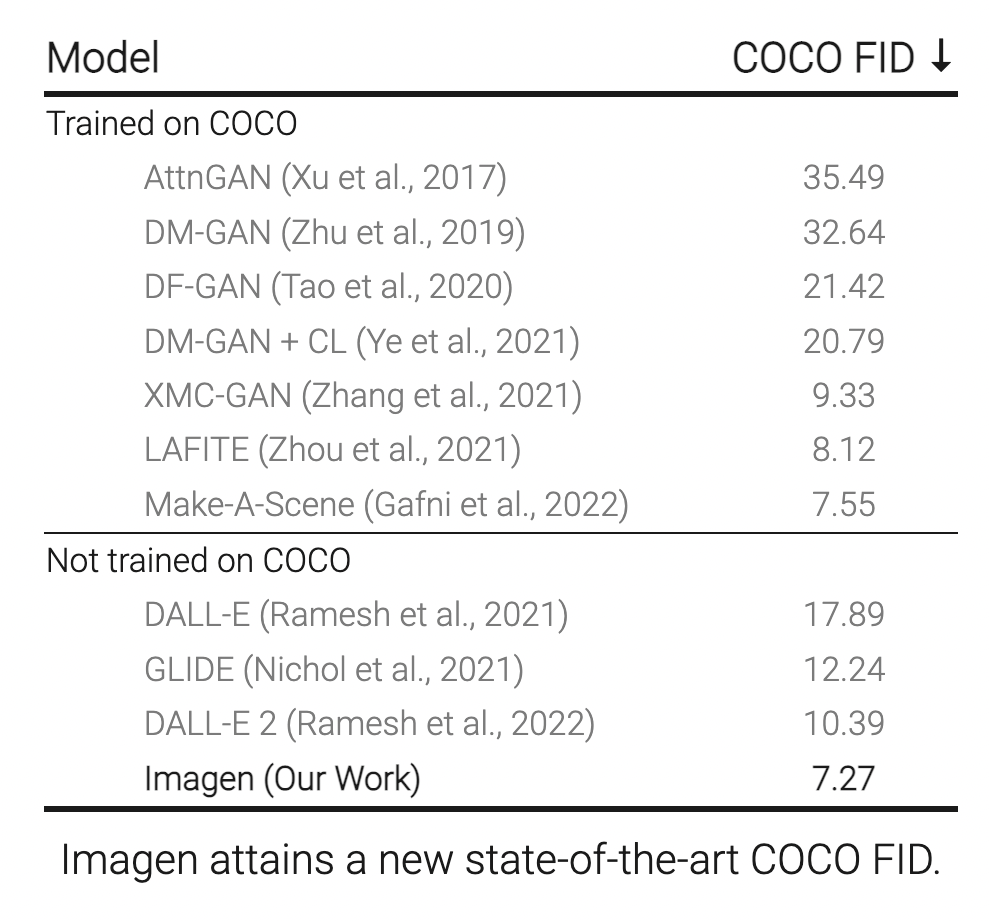 De FID-score van Imagen scoorde ruim boven andere tekst-naar-beeld-synthesizers. Google Onderzoek, Hersenteam
De FID-score van Imagen scoorde ruim boven andere tekst-naar-beeld-synthesizers. Google Onderzoek, Hersenteam
Om de resultaten te meten, gebruikte Imagen de Common Objects in Context (COCO) dataset, een open-source compendium van visuele datasets waarop bedrijven en onderzoekers hun AI-algoritmen kunnen trainen in beeldherkenning. De modellen ontvangen een Frechet Inception Distance (FID)-score, die hun nauwkeurigheid berekent bij het weergeven van een afbeelding op basis van aanwijzingen uit de dataset. Een lagere score geeft aan dat er meer overeenkomsten zijn tussen de echte en gegenereerde afbeeldingen, met een perfecte score van 0,0. Google's Imagen-diffusiemodel kan 1024-bij-1024-pixel voorbeeldafbeeldingen maken met een FID-score van 7,27.
Volgens de onderzoekspaper staat Imagen bovenaan de hitlijsten met zijn FID-score in vergelijking met andere modellen, waaronder DALL-E 2, VQ-GAN+CLIP en Latent Diffusion Models. Bevindingen gaven aan dat Imagen ook de voorkeur had van menselijke beoordelaars.
 Een drakenvrucht die een karateriem draagt, is slechts een van de vele afbeeldingen die Imagen kan maken. Google Onderzoek, Hersenteam
Een drakenvrucht die een karateriem draagt, is slechts een van de vele afbeeldingen die Imagen kan maken. Google Onderzoek, Hersenteam
"Voor fotorealisme behaalt Imagen een voorkeurspercentage van 39,2%, wat wijst op een hoge beeldkwaliteit", melden computerwetenschappers van Google. “Op de set zonder mensen is het voorkeurspercentage van Imagen gestegen tot 43,6%, wat wijst op het beperkte vermogen van Imagen om fotorealistische mensen te genereren. Wat de gelijkenis van bijschriften betreft, is de score van Imagen vergelijkbaar met de originele referentiebeelden, wat suggereert dat Imagen in staat is om afbeeldingen te genereren die goed aansluiten bij COCO-onderschriften.”
Naast de COCO-dataset heeft het Google-team ook hun eigen dataset gemaakt, die ze DrawBench noemden. De benchmark bestaat uit rigoureuze scenario's die het vermogen van verschillende modellen testten om afbeeldingen te synthetiseren op basis van "compositionaliteit, kardinaliteit, ruimtelijke relaties, lange tekst, zeldzame woorden en uitdagende prompts", die verder gaan dan de meer beperkte COCO-prompts.
 Hoewel leuk, de technologie presenteert morele en ethische dilemma's. Google Onderzoek, Hersenteam
Hoewel leuk, de technologie presenteert morele en ethische dilemma's. Google Onderzoek, Hersenteam
Morele implicaties van Imagen en andere AI tekst-naar-beeld software
Er is een reden waarom alle voorbeeldafbeeldingen geen mensen hebben. In hun conclusie bespreekt het Imagen-team de mogelijke morele gevolgen en maatschappelijke impact van de technologie, wat niet altijd het beste is. Het programma vertoont nu al een westerse vooringenomenheid en standpunt. Hoewel we erkennen dat er een potentieel is voor eindeloze creativiteit, zijn er helaas ook mensen die zouden kunnen proberen de software te misbruiken. Het is onder meer om deze reden dat Imagen niet beschikbaar is voor openbaar gebruik, maar dat kan veranderen.
"Aan de andere kant kunnen generatieve methoden worden gebruikt voor kwaadaardige doeleinden, waaronder intimidatie en de verspreiding van verkeerde informatie, en veel zorgen oproepen over sociale en culturele uitsluiting en vooroordelen", schrijven de onderzoekers. “Deze overwegingen vormen de basis voor onze beslissing om geen code of een openbare demo vrij te geven. In toekomstige werkzaamheden zullen we een raamwerk voor verantwoorde externalisering onderzoeken dat de waarde van externe controle in evenwicht houdt met de risico's van onbeperkte open toegang."
 De onderzoekers erkennen dat er meer werk nodig is voordat Imagen op verantwoorde wijze aan het publiek kan worden vrijgegeven. Google Onderzoek, Hersenteam
De onderzoekers erkennen dat er meer werk nodig is voordat Imagen op verantwoorde wijze aan het publiek kan worden vrijgegeven. Google Onderzoek, Hersenteam
Bovendien merkten de onderzoekers op dat vanwege de beschikbare datasets waarop Imagen is getraind, het programma vooringenomen is. "Dataset-audits hebben aangetoond dat deze datasets vaak sociale stereotypen, onderdrukkende standpunten en denigrerende of anderszins schadelijke associaties met gemarginaliseerde identiteitsgroepen weerspiegelen."
Hoewel de technologie zeker leuk is (wie wil er nu niet een afbeelding van een buitenaardse octopus die door een portaal zweeft terwijl hij een krant leest?), is het duidelijk dat er meer werk en onderzoek voor nodig is voordat Imagen (en andere programma's) kan worden verantwoord vrijgegeven aan het publiek. Sommige, zoals Dall-E 2, hebben beveiligingen ingezet, maar de doeltreffendheid valt nog te bezien. Imagen erkent de gigantische, maar noodzakelijke taak om de negatieve gevolgen grondig te verzachten.
"Hoewel we deze uitdagingen in dit werk niet direct aanpakken, is het besef van de beperkingen van onze trainingsgegevens leidend bij onze beslissing om Imagen niet vrij te geven voor openbaar gebruik", besluiten ze. "We waarschuwen ten zeerste tegen het gebruik van tekst-naar-afbeelding-generatiemethoden voor gebruikersgerichte tools zonder zorgvuldige zorg en aandacht voor de inhoud van de trainingsdataset."
Het bericht Waarom je Google's indrukwekkende tekst-naar-beeldgenerator Imagen niet kunt gebruiken, verscheen nog eerst op Popular Science.





