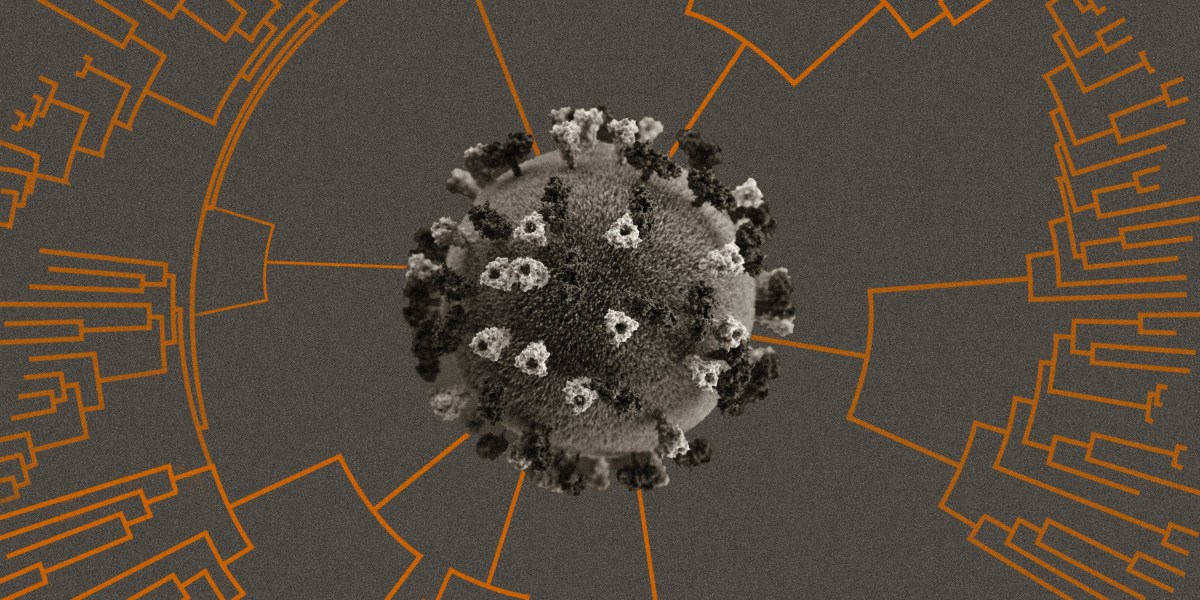
Ontmoet de mensen die de wereld waarschuwen voor nieuwe covid-varianten
In maart, toen covid-gevallen in India begonnen toe te nemen, ging Bani Jolly op zoek naar antwoorden in de genetische code van het virus.
Onderzoekers in het VK hadden net de wetenschappelijke wereld in vuur en vlam gezet met nieuws dat een covid-variant genaamd B.1.1.7 – binnenkort alfa genoemd – verantwoordelijk was voor het torenhoge aantal gevallen daar. Jolly, een derdejaars promovendus aan het CSIR Institute of Genomics and Integrative Biology in New Delhi, verwachtte dat het ook in haar land infecties veroorzaakte.
Omdat haar instelling voorop loopt op het gebied van covid-onderzoek in India, had ze toegang tot sequenties van duizenden covid-monsters die in het hele land waren genomen. Ze begon ze door software te laten lopen die ze groepeerde volgens takken van de stamboom van covid.
In plaats van dichte opeenhopingen van B.1.1.7-gevallen vond Jolly een cluster van sequenties die er niet echt uitzagen als een bekende variant, sommige met twee mutaties van het spike-eiwit waarvan al werd vermoed dat ze het virus gevaarlijker maakten.
Jolly sprak met haar adviseur, die voorstelde om contact op te nemen met andere sequencing-laboratoria in India. Ook hun gegevens vertoonden tekenen dat een lokale uitbraak aanleiding had gegeven tot een nieuwe familie van het virus.
Het duurde niet lang of journalisten kregen lucht van de nieuwe ontwikkeling en Jolly begon artikelen te zien over 'dubbele mutanten' en de 'Indiase variant'.
Ze wist dat onderzoekers meer konden doen met een handig label dan met een 'scariant'-bijnaam. Dus ging ze naar de plek waar een kleine groep wetenschappers nieuwe varianten hun naam geeft: een GitHub-pagina bemand door een handvol vrijwilligers over de hele wereld, voornamelijk geleid door een promovendus in Schotland.
Die vrijwilligers houden toezicht op een systeem genaamd Pango, dat stilletjes essentieel is geworden voor wereldwijd covid-onderzoek. De softwaretools en het naamgevingssysteem hebben wetenschappers nu wereldwijd geholpen om bijna 2,5 miljoen monsters van het virus te begrijpen en te classificeren.
In april plaatste Jolly haar sequenties op de GitHub-pagina, samen met een uitleg waarom ze een belangrijke verandering in het virus vormden. (Ze was de tweede gebruiker die de nieuwe variant markeerde; de eerste vlag was een paar dagen eerder gezwaaid door een onderzoeker in het VK.) Het Pango-team kwam snel met een nieuwe naam, B.1.167. De familie omvat de beruchte overdraagbare variant die nu in de media bekend staat als delta.
"Pango maakt het heel gemakkelijk om te zien of andere mensen zien wat wij zien", zegt Jolly. "Als dat niet het geval is, is het heel eenvoudig om te melden wat er in India wordt gezien, zodat mensen het in andere regio's kunnen volgen."
Onderzoekers, volksgezondheidsfunctionarissen en journalisten over de hele wereld gebruiken Pango om de evolutie van covid te begrijpen. Maar weinigen realiseren zich dat het hele streven – zoals veel op het nieuwe gebied van covid-genomica – wordt aangedreven door een klein team van jonge onderzoekers die vaak hun eigen werk in de wacht hebben gezet om het op te bouwen.
Te veel gegevens
Je zou kunnen aannemen dat er al lang een officieel, beproefd proces is voor het benoemen van nieuwe takken van de stamboom van een virus terwijl deze zich ontwikkelt, waarbij de ene persoon na de andere wordt geïnfecteerd. Onderzoekers gebruiken immers al twee decennia genomische sequencing om virussen te bestuderen.
Maar dat werk heeft historisch gezien te maken gehad met orden van grootte minder gegevens, en weinig ervan werd gezamenlijk gedeeld tussen wetenschappers op verschillende continenten, zoals covid-sequenties zijn geweest. Er was nooit een dringende behoefte geweest om gestandaardiseerde namen te ontwikkelen.
In maart 2020, toen de WHO een pandemie uitriep, bevatte de openbare sequentiedatabase GISAID 524 covid-sequenties. In de loop van de volgende maand uploadden wetenschappers 6.000 meer. Eind mei was het totaal meer dan 35.000. (Daarentegen hebben wereldwijde wetenschappers in heel 2019 40.000 griepsequenties aan GISAID toegevoegd.)
"Zonder een naam, vergeet het maar – we kunnen niet begrijpen wat andere mensen zeggen", zegt Anderson Brito, een postdoc in genomische epidemiologie aan de Yale School of Public Health, die bijdraagt aan de Pango-inspanning.
Naarmate het aantal covid-sequenties in een stroomversnelling raakte, werden onderzoekers die ze probeerden te bestuderen gedwongen om direct een geheel nieuwe infrastructuur en normen te creëren. Een universeel naamgevingssysteem is een van de belangrijkste elementen van deze inspanning geweest: zonder dit zouden wetenschappers moeite hebben om met elkaar te praten over hoe de afstammelingen van het virus reizen en veranderen – ofwel om een vraag te signaleren of, nog belangrijker, om sla alarm.
Waar Pango vandaan kwam
In april 2020 stelde een handvol prominente virologen in het VK en Australië een systeem van letters en cijfers voor voor het benoemen van afstammelingen, of nieuwe takken, van de covid-familie. Het had een logica en een hiërarchie, ook al waren de namen die het genereerde – zoals B.1.1.7 – een beetje een mondvol.
Een van de auteurs op het artikel was Áine O'Toole, een promovendus aan de Universiteit van Edinburgh. Al snel zou ze de eerste persoon worden die dat sorteert en classificeert, en uiteindelijk honderdduizenden reeksen met de hand doorkamt.
Ze zegt: “Al heel vroeg was het precies wie beschikbaar was om de sequenties te cureren. Dat is uiteindelijk voor een tijdje mijn werk geworden. Ik denk dat ik nooit de omvang heb begrepen die we zouden bereiken."
Ze begon snel met het bouwen van software om nieuwe genomen aan de juiste afstammingslijnen toe te wijzen. Niet lang daarna bouwde een andere onderzoeker, postdoc Emily Scher, een machine learning-algoritme om de zaken nog sneller te maken.
"Zonder een naam, vergeet het – we kunnen niet begrijpen wat andere mensen zeggen."
Anderson Brito, Yale School of Public Health
Ze noemden de software Pangolin, een ironische verwijzing naar een debat over de dierlijke oorsprong van covid. (Het hele systeem is nu gewoon bekend als Pango.)
Het naamgevingssysteem, samen met de software om het te implementeren, werd al snel een wereldwijd essentieel onderdeel. Hoewel de WHO onlangs Griekse letters is gaan gebruiken voor varianten die bijzonder zorgwekkend lijken, zoals delta, zijn die bijnamen voor het publiek en de media. Delta verwijst eigenlijk naar een groeiende familie van varianten, die wetenschappers bij hun preciezere Pango-namen noemen: B.1.617.2, AY.1, AY.2 en AY.3.
"Toen alfa in het VK opdook, maakte Pango het ons heel gemakkelijk om naar die mutaties in onze genomen te zoeken om te zien of we die afstamming ook in ons land hadden", zegt Jolly. "Sindsdien wordt Pango gebruikt als basis voor rapportage en bewaking van varianten in India."
Omdat Pango een rationele, ordelijke benadering biedt van wat anders chaos zou zijn, kan het voor altijd de manier veranderen waarop wetenschappers virale stammen noemen – waardoor experts van over de hele wereld kunnen samenwerken met een gedeeld vocabulaire. Brito zegt: "Hoogstwaarschijnlijk zal dit een formaat zijn dat we zullen gebruiken om elk ander nieuw virus op te sporen."
Veel van de fundamentele hulpmiddelen voor het volgen van covid-genomen zijn de afgelopen anderhalf jaar ontwikkeld en onderhouden door wetenschappers uit het begin van hun carrière, zoals O'Toole en Scher. Toen de behoefte aan wereldwijde covid-samenwerking explodeerde, haastten wetenschappers zich om het te ondersteunen met ad-hocinfrastructuur zoals Pango. Veel van dat werk viel op jonge technisch onderlegde onderzoekers van in de twintig en dertig. Ze gebruikten informele netwerken en tools die open source waren, wat betekent dat ze gratis te gebruiken waren en dat iedereen zich vrijwillig kon aanmelden om tweaks en verbeteringen toe te voegen.
"De mensen op het snijvlak van nieuwe technologieën zijn meestal afgestudeerde studenten en postdocs", zegt Angie Hinrichs, een bio-informaticus aan UC Santa Cruz die eerder dit jaar bij het Pangolin-project kwam. O'Toole en Scher werken bijvoorbeeld in het laboratorium van Andrew Rambaut, een genomische epidemioloog die de eerste openbare covid-sequenties online plaatste nadat ze deze van Chinese wetenschappers hadden ontvangen. "Ze waren toevallig perfect geplaatst om deze tools te leveren die absoluut cruciaal werden", zegt Hinrichs.
Snel bouwen
Het is niet gemakkelijk geweest. Het grootste deel van 2020 nam O'Toole het grootste deel van de verantwoordelijkheid voor het identificeren en benoemen van nieuwe geslachten zelf op zich. De universiteit was gesloten, maar zij en een andere promovendus van Rambaut, Verity Hill, kregen toestemming om het kantoor binnen te komen. Haar woon-werkverkeer, 40 minuten lopen naar school vanaf het appartement waar ze alleen woonde, gaf haar een gevoel van normaliteit.
Om de paar weken downloadde O'Toole de hele covid-repository uit de GISAID-database, die elke keer exponentieel was gegroeid. Daarna ging ze op zoek naar groepen genomen met mutaties die er hetzelfde uitzagen, of dingen die er vreemd uitzagen en misschien verkeerd waren gelabeld.
Als ze vast kwam te zitten, kwamen Hill, Rambaut en andere leden van het lab binnen om de benamingen te bespreken. Maar het gromwerk viel op haar.
"Stel je voor dat je 20.000 sequenties doorloopt van 100 verschillende plaatsen in de wereld. Ik zag sequenties van plaatsen waar ik nog nooit van had gehoord.”
Áine O'Toole, Universiteit van Edinburgh
Beslissen wanneer afstammelingen van het virus een nieuwe familienaam verdienen, kan net zoveel kunst zijn als wetenschap. Het was een moeizaam proces, het doorzoeken van een ongekend aantal genomen en keer op keer vragen: is dit een nieuwe variant van covid of niet?
"Het was behoorlijk vervelend", zegt ze. “Maar het was altijd heel vernederend. Stel je voor dat je door 20.000 sequenties gaat vanuit 100 verschillende plaatsen in de wereld. Ik zag sequenties van plaatsen waar ik nog nooit van had gehoord.”
Naarmate de tijd verstreek, worstelde O'Toole met het bijhouden van de hoeveelheid nieuwe genomen om te sorteren en te benoemen.
In juni 2020 waren er meer dan 57.000 sequenties opgeslagen in de GISAID-database en O'Toole had ze gesorteerd in 39 varianten. In november 2020, een maand nadat ze haar scriptie moest inleveren, nam O'Toole haar laatste solo-run door de gegevens. Het kostte haar 10 dagen om alle reeksen te doorlopen, die toen 200.000 waren. (Hoewel covid haar onderzoek naar andere virussen heeft overschaduwd, schrijft ze een hoofdstuk over Pango in haar proefschrift.)
Gelukkig is de Pango-software gebouwd om samen te werken, en anderen zijn opgevoerd. Een online community – de community waar Jolly zich op richtte toen ze merkte dat de variant door India raasde – groeide en groeide. Dit jaar was het werk van O'Toole veel meer hands-off. Nieuwe geslachten worden nu meestal aangewezen wanneer epidemiologen over de hele wereld contact opnemen met O'Toole en de rest van het team via Twitter, e-mail of GitHub – haar voorkeursmethode.
"Nu is het meer reactionair", zegt O'Toole. "Als een groep onderzoekers ergens in de wereld aan wat gegevens werkt en ze denken een nieuwe afstamming te hebben geïdentificeerd, kunnen ze een verzoek indienen."
De stortvloed aan gegevens houdt aan. Afgelopen voorjaar hield het team een 'pangothon', een soort hackathon waarin ze 800.000 sequenties in ongeveer 1.200 geslachten sorteerden.
"We hebben onszelf drie stevige dagen gegeven", zegt O'Toole. "Het heeft twee weken geduurd."
Sindsdien heeft het Pango-team nog een paar vrijwilligers geworven, zoals UCSC-onderzoeker Hindriks en Yale-onderzoeker Brito, die beiden aanvankelijk betrokken raakten door hun twee cent toe te voegen op Twitter en de GitHub-pagina. Een postdoc aan de Universiteit van Cambridge, Chris Ruis, heeft zijn aandacht gericht op het helpen van O'Toole om de achterstand van GitHub-verzoeken weg te werken.
O'Toole vroeg hen onlangs om formeel lid te worden van de organisatie als onderdeel van het nieuw opgerichte Pango Network Lineage Designation Committee , dat de namen van varianten bespreekt en neemt. Een andere commissie, waaronder laboratoriumleider Rambaut, neemt beslissingen op hoger niveau.
"We hebben een website en een e-mail die niet alleen mijn e-mail is", zegt O'Toole. "Het is veel geformaliseerder geworden, en ik denk dat dat echt zal helpen om het op te schalen."
De toekomst
Er zijn een paar scheuren aan de randen zichtbaar geworden naarmate de gegevens zijn gegroeid. Vanaf vandaag zijn er bijna 2,5 miljoen covid-sequenties in GISAID, die het Pango-team heeft opgesplitst in 1.300 vestigingen. Elke tak komt overeen met een variant. Daarvan zijn er acht om in de gaten te houden, aldus de WHO.
Met zoveel te verwerken, begint de software te bezwijken. Dingen worden verkeerd gelabeld. Veel stammen lijken op elkaar, omdat het virus keer op keer de meest voordelige mutaties ontwikkelt.
Als noodmaatregel heeft het team nieuwe software gebouwd die een andere sorteermethode gebruikt en dingen kan opvangen die Pango misschien mist.
Het is echter belangrijk om te onthouden dat geen enkel systeem ooit te maken heeft gehad met zo'n stortvloed aan gegevens over hoe virussen veranderen. Covid is het meest bekeken virus aller tijden geworden. Het is ook de eerste keer dat wetenschappers precies kunnen zien hoe het virus verandert terwijl het zich tussen landen verplaatst.
"Dit alles was mogelijk omdat mensen hun gegevens deelden, mensen hun tools deelden", zegt Jolly.
Omdat wetenschappers manieren hebben gevonden om met elkaar te communiceren, moesten ze ook leren over openbare communicatie. Het was "een beetje surrealistisch", zegt O'Toole, kijkend naar de media die deze zeer technische namen gebruiken.
"We hebben deze nomenclatuur het hele jaar door gebruikt, en het is echt nuttig voor de wetenschappelijke gemeenschap, maar een naam als B.1.1.7 was absoluut niet ontworpen om op BBC News te staan", zegt ze. "Het was een grote leerervaring om dit niveau van publieke controle te hebben."
Achter de schermen blijft het Pango-team de evolutie van covid volgen, zodat wetenschappers over de hele wereld kunnen samenwerken om de pandemie te stoppen.
Brito: “De media hebben het de hele tijd over de deltavariant, de alfavariant. CNN Brazilië heeft het over het genoom waarvan de sequentie wordt bepaald en zegt: 'De afstamming zal worden toegewezen en we zullen over een paar dagen een rapport krijgen' … Twee jaar geleden zou het ondenkbaar zijn geweest.'
Dit verhaal maakt deel uit van het Pandemic Technology Project , ondersteund door The Rockefeller Foundation.



![Meta snijdt aanwervingsplannen terwijl het zich voorbereidt op 'ernstige tijden' In een wekelijkse Q&A-sessie voor medewerkers zei Meta-CEO Mark Zuckerberg naar verluidt dat het bedrijf "een van de ergste recessies in de recente geschiedenis doormaakt". Volgens Reuters heeft de uitvoerende macht onthuld dat Meta zijn streefaantal voor nieuwe ingenieurs dit jaar met ongeveer 30 procent heeft verlaagd. Meta zei eerder dat het zijn aanwervingsplannen vertraagt vanwege zwakke omzetprognoses, maar nu heeft Zuckerberg meer details bekendgemaakt met exacte cijfers. Blijkbaar zal Meta, van plannen om dit jaar 10.000 nieuwe ingenieurs in dienst te nemen, slechts tussen de 6.000 en 7.000 aannemen. Verder zei de CEO dat Meta de verwachtingen van de huidige werknemers verhoogt en hen agressievere doelen geeft, zodat ze zelf kunnen beslissen of het bedrijf niet voor hen is. "[S]elf-selectie is OK met mij," zei hij. In een memo aan werknemers heeft Chief Product Officer Chris Cox benadrukt dat het bedrijf "zich in ernstige tijden bevindt en de tegenwind hevig is". Hij somde ook de zes investeringsprioriteiten van het bedrijf op voor de tweede helft van het jaar, te beginnen met de metaverse initiatieven Avatars en de virtuele wereld Horizon Worlds. Volgens de memo, volledig gepubliceerd door The Verge, streeft Meta er ook naar om zo snel mogelijk geld te verdienen met Reels. De tijd die aan Reels wordt besteed, is sinds vorig jaar wereldwijd meer dan verdubbeld, zo staat in de memo, waarbij 80 procent van die groei afkomstig is van Facebook. Cox noemde Reels, het korte videoformaat gemaakt als antwoord op TikTok, een "lichtpuntje" voor het bedrijf in de eerste helft van 2022. Meta is van plan de ervaring te blijven verbeteren, inclusief het aanbrengen van wijzigingen in het startscherm op Instagram en Facebook om de video's meer native op te nemen. Daarnaast is Meta van plan zich in de tweede helft van het jaar te concentreren op haar AI-initiatieven, evenals op WhatsApp en Messenger. Het is van plan WhatApp-gemeenschappen te testen voordat de functie eind 2022 over de hele wereld wordt gelanceerd. Het bedrijf gaat ook Instagram Creator-kanalen en koppelbare chats ontwikkelen, die in de komende maanden zullen worden uitgerold. Cox schreef in de memo: "Ik moet onderstrepen dat we ons hier in ernstige tijden bevinden en dat de tegenwind hevig is. We moeten feilloos presteren in een omgeving van tragere groei, waar teams geen enorme toestroom van nieuwe ingenieurs en budgetten mogen verwachten. We moeten meedogenlozer prioriteiten stellen, nadenken over het meten en begrijpen van wat impact drijft, investeren in de efficiëntie en snelheid van ontwikkelaars binnen het bedrijf, en slankere, gemenere, betere opwindende teams runnen."](https://stilgehouden.nl/wp-content/uploads/2022/07/meta-snijdt-aanwervingsplannen-terwijl-het-zich-voorbereidt-op-ernstige-tijden-in-een-wekelijkse-qa-sessie-voor-medewerkers-zei-meta-ceo-mark-zuckerberg-naar-verluidt-dat-het-bedrijf-q-800x450.jpg)

